Knative Autoscaling 연구하기
안녕하세요.
이전 포스팅에서 Serving과 Eventing 그리고 Auto Scaling에 대해서 알아보았습니다. Knative의 Auto Scaling은 기존의 Metric, Event 방식의 Autoscaler들과는 달리 KPA(Knative Pod Autoscaler)에 의해 Concurrency 즉, Request 수에 따라 Autoscaling이 이루어지게 됩니다.
따라서 이번 포스팅에서는 Knative에서 Auto Scaling이 내부적으로 어떻게 동작하고 어떻게 구현되어있는지 그리고 어떠한 수식과 로직에 따라계산되는지 등에 대해 코드레벨에서 분석한 내용을 말씀드리고자합니다.
* 코드의 내용이 방대하여 전체 코드를 세세하게 보진 못하여 틀린 부분이 있다면 말씀주시면 감사한 마음으로 수정하겠습니다. :)
Autoscaler Summary
흔히 말하는 Autoscaling은 다양한 형태로 다양한 메트릭을 통해 이루어질 수 있습니다. 컨테이너 이전 VM 환경에서도 일반적으로 Scale Up/Down은 대상에 대한 리소스의 크기를 조절하는 것입니다. 그러나 대부분의 Scale Up/Down 기술은 일반적으로 재시작이라는 리스크가 있어 서비스의 중단이 될 수 있습니다. 이러한 리소스 Scaling 외에 대상 자체에 대한 수를 조절하는 Scaling이 있고 이를 Scale In/Out이라고 합니다 .
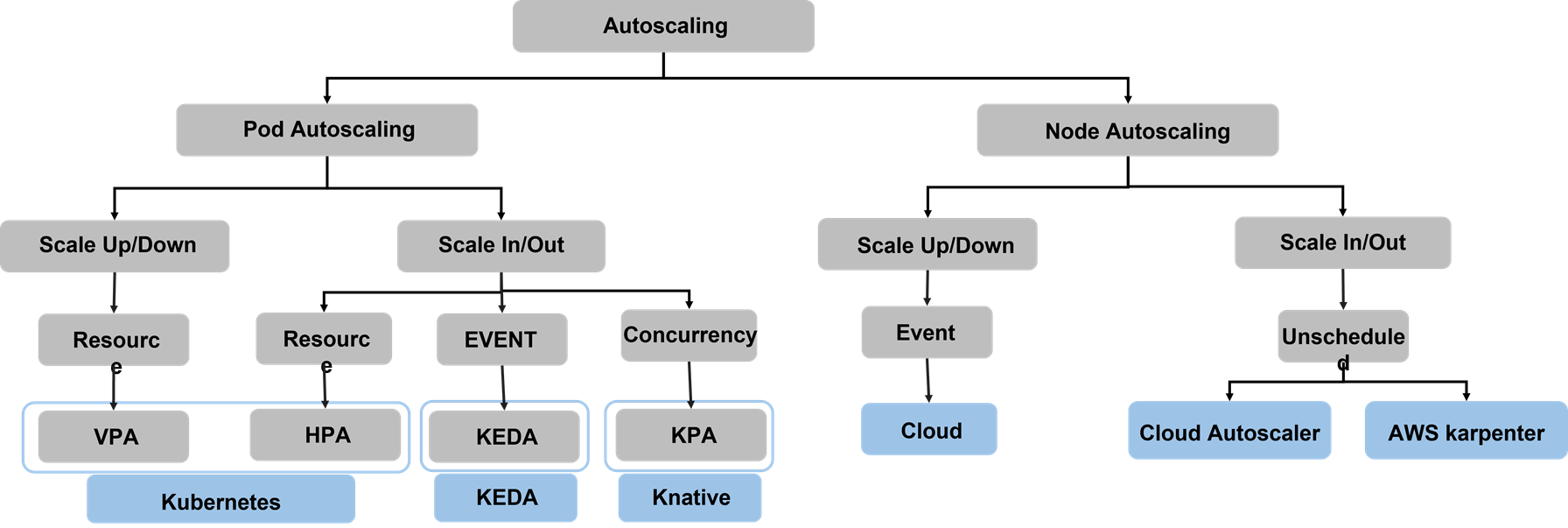
그림 1에서는 Autoscaling에 대해 요약을 그림을 나타냅니다. Container 환경에서의 Autoscaling은 크게 Pod Scaling과 Node Scaling이 있습니다. 각각의 Scaling은 각각 Scale Up/Down 그리고 In/Out으로 나뉘어집니다. 이렇게 Scale 작업이 이루어지기 위해서는 사용자가 사전에 정의한 ResourceTarget값을 수집한 Resouce 값과 비교하여 Scaling Action을 발생 시키는 방식이 있고, 외부 프로젝트와 연동을 통해 발생한 Event를 수신하여 Scaling Trigger를 발생시킬 수도 있습니다.
현재 Kubernetes에서는 Scale Up/Down과 Scale In/Out 방식을 VPA(Vertical Pod Autoscaler)와 HPA(Horizontal Pod Autoscaler)로 각각 지원하고 있습니다. 다만 두 방식 모두 동시에 같은 Metric (CPU,Mem)을 통해 함께 사용하는 것은 권장하지 않고 있습니다.
그 다음으로 외부 프로젝트(e.g. 모니터링)에서 발생하는 이벤트등을 감지하여 Scaling Action을 수행하도록 하는 Event 기반 Scaler인 KEDA가 있습니다. Node Autoscaler는 주로 Pod가 동작하는 Worker Node에 대한 Scaling 기능을 제공하는데, Event 혹은 Monitoring 기반의 Scale Up/Down은 이미 오픈스택의 프로젝트들을 통해 제공받을 수 있습니다.
Scale In/Out의 경우에는 Pod 생성 시 Pending 상태인지를 모니터링하다가 해당 상태가 지속되면 Worker Node의 리소스 부족으로 인지하고 Worker Node를 생성하고 이를 기존에 Kubernetes Cluster에 Join하여 Pod가 생성될 수있도록 합니다. 대표적으로 Cloud Autoscaler 혹은 AWS Karpenter가 있습니다.
Knative Autoscaler
앞에서 간략하게 말씀드렸던 Metric, Event 기반 Scaler 외에도 Knative에서 사용중인 Autoscaler인 KPA (Knative Pod Autoscaler)는 Request 수를 기반으로 Autoscaling을 하게 됩니다. 따라서 Knative가 사용하는 Autoscaling의 가장 중요한 지표는 Request 수와 시간이라고 볼 수 있습니다.
이전 Knative Autoscaling 포스팅에서도 말씀드렸으나, Knative가 Autoscaling을 하기 위해서 필요한 컴포넌트들은 아래와 같이 요약 설명 될 수있습니다.
- Queue Proxy : Knative Pod에서 User Container와 함께 배포되어 사이드카 컨테이너 형태로 Request수를 카운팅하거나, Concurrency 계산 및 사용자가 설정한 Target에 따라 Request를 제한하는 기능을 제공
- Autoscaler : Queue Proxy로부터 현재 계산된 평균 Concurrency 값을 기반으로 사용자가 설정한 Target 값과 비교하여 Scaling In/Out Action을 수행
- Activator : 동작중인 Pod가 없는 상태에서 요청이 왔을 경우 요청을 버퍼링하고, 요청 수등을 Autoscaler에게 전달
- SKS : Serve/Proxy모드로 변환하여 Public Service의 Endpoint가 Pod 혹은 Activator를 향하게 함
Knative의 Autoscaler는 Autoscaling에 가장 핵심적인 기능을 가지고 있다고 볼 수 있습니다. Kubernetes를 통해 Replica의 수를 조절하여 Pod의 개수를 조정하거나, Activator로부터 초기 Request를 가지기 위한 Server 및 User Pod의 Queue-Proxy에서 계산한 통계값(Concurrency)을 처리하는 여러가지 기능을 수행합니다.
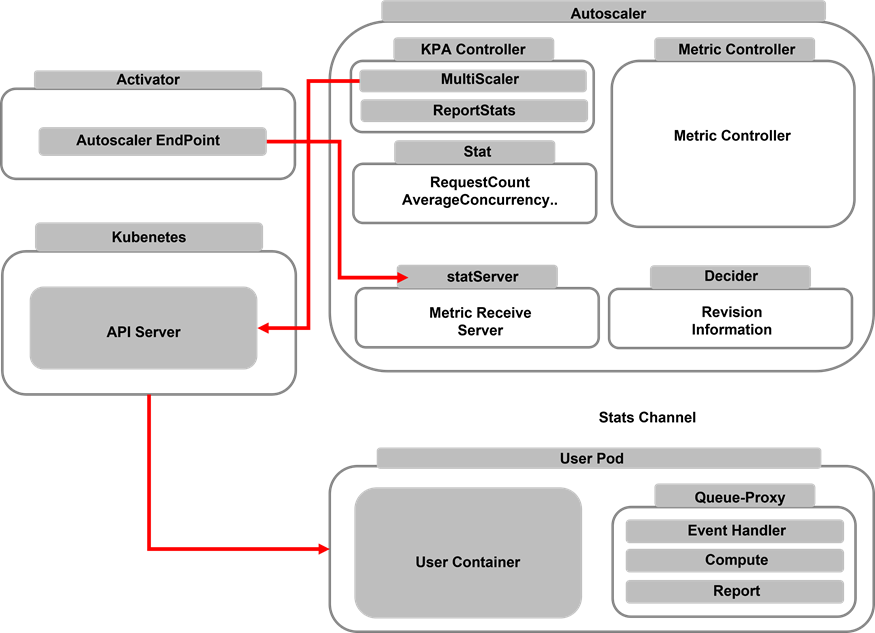
그림 2에서는 이러한 Autoscaling에 대해 코드 레벨에서 대략적인 기능을 분류하였습니다. 우선 Activator는 Pod의 수가 0일 경우 Service로부터 가장 먼저 데이터를 받고 이러한 Data를 Autoscaler쪽으로 전달하게 되는데 Activator 코드 내부에는 Autoscaler로 Data를 보내기 위한 Endpoint 주소가 정의되어있습니다. 해당 Endpoint를 통해 Activator는 Data를 전달하게 됩니다. statServer는 반대로 Metric, Report등에 대한 정보를 수신하는 API Server로 생각할 수 있습니다.
Autoscaler에는 KPA Controller가 정의되어 있습니다. KAP Controller는 크게 Multiscaler, ReportStats가 있습니다. ReportStats는 Stat Value(Concurrency, Revision Name)가 담겨있는 stat 구조체를 처리하는 기능을 하고 있으며, MultiScaler는 이렇게 처리된 Stat 구조체의 값에 따라 Kubernetes API Server를 통해 Pod의 Replica 수를 조절하게 됩니다 . 그 외에 Decider, Stat은 Proxy로부터 전달된 Concurrency 및 Namespace, Pod명 등에 대한 정보를 가지고 있는 구조체로 볼 수 있습니다.
이렇게 대략적으로 Autoscaling을 구성하는 컴포넌트와 개념들을 간단하게 코드레벨에서 확인해 보았습니다. 그러나 Autoscaler의 경우 코드 내부에 HPA, KPA를 사용하기 위한 코드들이 모두 정의 되어있고 각각 Autoscale을 위한 기준값에 따라 선택적으로 사용할 수 있습니다.
KPA의 경우에는 CPU를 기반으로하는 Autoscaling은 지원하지 않고, HPA만 CPU를 기반으로 지원하고 있습니다. 다만 KPA에서만 Scale to Zero 기능을 지원하고 HPA는 지원하고 있지 않습니다. 이러한 KPA는 Concurrency에 따라 2가지의 Mode로 자동적으로 변환되는데 기본 모드인 Stable 모드는 60초를 기준으로 설정된 Concurrecy Target값에 따라 pod의 수를 안정적으로 조절하게 됩니다. 60초를 기준으로 평균 요청 수를 계산하여 Stable 모드를 유지하는데 이렇게 계산된 평균 요청수가 Concurrency Target 값의 2배가 되는경우 KPA는 모드를 Panic으로 변경하게 되며, 60초 주기가 아닌 6초 동안의 주기를 기준으로 계산하게 됩니다. 이를 통해 더욱 짧은 시간동안 발생하는 평균 요청 수를 계산하여 Scaling을 더욱 빠르고 민감하게 발생 시킬 수있게 됩니다.
Autoscaler는 이렇게 Concurrency를 계산하고 사용자가 설정한 Target Concurrency와 비교하게 됩니다. Concurrency Metric의 경우 각각 Soft Limit과 Hard Limit이 있습니다. Soft Limit의 경우에는 어느정도 Concurrency가 초과 될 수 있음을 의미합니다. 만약 Request가 100개이고 Taget이 10인 경우 100/10으로 Pod는 10개를 생성하게 됩니다. Limit의 경우 절대적으로 해당 수치를 넘지 말아야하는 것을 의미합니다.
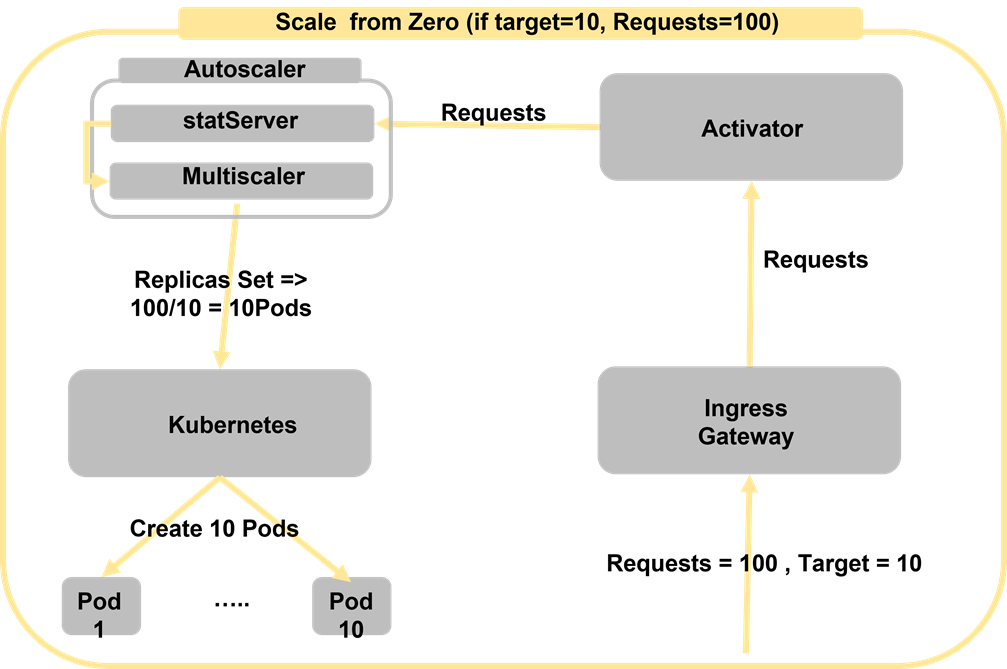
그림 3에서는 Scale from zero에 따란 간단한 로직을 설명합니다. Request가 100개를 요청하였고, 해당 Pod에 대해 Target 값이 10으로 설정 되어 있는 경우 각 Pod당 10개의 요청을 병렬로 분산시키기 위해 10개의 Pod를 생성하게 됩니다. Ingress Gateway는 요청을 수신하고, Activator->Autoscaler로 전달되면서 필요한 Pod의 수를 계산하고 Kubernetes를 통해 계산된 Pod의 수 만큼 생성 하게 됩니다.

마찬가지로 그림 4에서는 Queue-Proxy에서 계산된 평균 Concurrency가 일정 시간동안 0인 경우 Autoscaler는 Replica 수를 0으로 조정하여 Pod를 삭제하게 됩니다.

그림 5에서는 Queue Proxy에서 어떻게 Average Concurrency를 계산하는지에 대해 그림으로 나타내었습니다. Queue Proxy는 그림 2에서 보신 것처럼 크게 EventHandler, Compute, Report가 존재하게 됩니다. EventHandler는 가장 먼저 이벤트를 수신하게 되고 이벤트 종류에 따라 Request를 Count 합니다. 그다음 Compute는 실질적으로 Average Concurrency 값을 도출하기 위해 이벤트 발생 시간동안 남아있는 Request Count값을 이벤트 발생 주기 즉 현재 시간과 최근 이벤트 시간의 차이를 계산하여 ComputedConcurrency에 Request 값과 주기를 곱하여 계속해서 누적시키게 됩니다 .
Computed Concurrency 값은 Requests 이벤트가 계속 발생하면 할수록 해당 값이 점점 커지게 됩니다. 이렇게 이벤트가 계속 수신되면서 약 1초정도 이벤트가 발생하지 않게 되면 Report 함수가 호출되면서 Computed Concurrency의 Average를 구하게 되는데 이때 1로나누게 됩니다.(큰 의미가 있는건지 별도 설정이 필요한건지는 확인해봐야할 것같습니다) 따라서 이렇게 Average Concurrency를 반환하게 됩니다.
결론적으로 Queue-Proxy는 현재 남아있는 Request Count를 계산하여 어느정도의 평균 Concurrency가 발생하고 있는지를 계산하여 Autoscaler에게 Report하게 됩니다. Request In이 연속적으로 들어온다면 평균 Concurrency의 값이 계속 높아지지만 반대로 Request Out 이벤트를 통해 Request Count가 줄어든다면 평균 Concurrency의 값이 줄어들게 됩니다.
결론
이번 포스팅에서는 Autoscaling 알고리즘에 대해 알아보았습니다. 코드 레벨에서 전반적인 기능 및 내용정도는 파악하였으나 아직까지는 조금더 확인해봐야할 부분이 많은 것 같습니다. 부족한 내용이지만 혹 수정사항이 있다면 언제든지 피드백 부탁드립니다. 감사합니다.
인용글
업데이트로그
--------------------------------------------------------------------------------------------------------------
해당 글은 스스로 연구한 내용을 통한 주관적인 이해를 바탕으로 작성 되었습니다. 수정 할 부분이 있거나, 다른 의견이 있으시다면 언제든지 말씀해주시면 반영하도록 하겠습니다. 읽어 주셔서 감사합니다. 끝으로 불법으로 복제하는 것은 금합니다.